EasyVVUQ - Vector Quantities of Interest¶
Author: Vytautas Jancauskas, LRZ (jancauskas@lrz.de)
It is often the case that simulation outputs are vector valued and represent changes over time in whatever phenomenon that is simulated. Here we examine how to analyse these cases with EasyVVUQ. As an example we use the following model from epidemiology - SIR. It compartmentalises the population into the following groups: (\(S\))usceptible, (\(I\))nfected and (\(R\))emoved. There are four input parameters to out model. They are initial number of susceptible people \(S_0\), initial number of infected people \(I_0\), transmission rate \(\beta\) and recovery rate \(\gamma\). The system is governed by three differential equations below. The number of suspectible people is reduced by them getting infected (and thus moving to \(I\)) at rate specified by \(\beta\). The number of infected people increases similarly. Finally the number of recovered people increases depending on the recovery rate and the number of people currently infected.
The simulation is run as shown below, where input_file is a JSON file of the following format: {"outfile": "$outfile", "S0": $S0, "I0": $I0, "beta": $beta, "gamma": $gamma, "iterations": $iterations}
sir <input_file>
Lets try and run it.
[1]:
!echo "{\"outfile\": \"output.csv\", \"S0\": 997, \"I0\": 3, \"beta\": 0.2, \"gamma\": 0.04, \"iterations\": 100}" > input.json
[2]:
!./sir input.json
The simulation code outputs a CSV file with a specified name. We can try opening it up and printing the first 10 lines.
[3]:
!head output.csv
S,I,R,r0,t
996.4018,3.47784108,0.1391136432,4982.009,1
995.7087475755611,4.0312978050411745,0.300365555401647,4978.543737877805,2
994.905980318425,4.672165937353743,0.4872521928957967,4974.5299015921255,3
993.9763679472093,5.4140230672294996,0.7038131155849767,4969.8818397360465,4
992.9001871310173,6.27247777694467,0.9547122266627635,4964.500935655087,5
991.654756898651,7.2654467105291545,1.2453300950839297,4958.273784493255,6
990.2140324288114,8.413460157063296,1.5818685013664615,4951.070162144058,7
988.548155936764,9.739995672478827,1.9714683282656145,4942.740779683821,8
986.6229648025937,11.27183768247915,2.4223418355647803,4933.11482401297,9
Finally lets plot the results.
[4]:
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('output.csv')
As we can see it shows the number of infected people increasing at first and then decreasing as the number of people who have recovered rises. Number of susceptible and recovered people also changes in a way that makes intuitive sense.
[5]:
plt.plot(df['S'], label='S')
plt.plot(df['I'], label='I')
plt.plot(df['R'], label='R')
plt.legend()
[5]:
<matplotlib.legend.Legend at 0x11dd68d00>
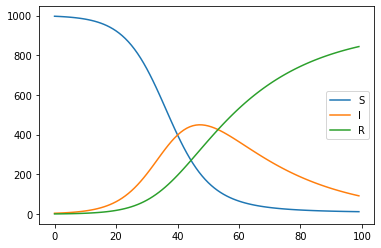
So let us see what EasyVVUQ can tell us about the distribution of the number of infected people over time. We will not go into the details of the EasyVVUQ API this time. Only where it differs from the basic concepts tutorial.
[6]:
import easyvvuq as uq
import chaospy as cp
import matplotlib.pyplot as plt
[7]:
params = {
"S0": {"type": "float", "default": 997},
"I0": {"type": "float", "default": 3},
"beta": {"type": "float", "default": 0.2},
"gamma": {"type": "float", "default": 0.04, "min": 0.0, "max": 1.0},
"iterations": {"type": "integer", "default": 100},
"outfile": {"type": "string", "default": "output.csv"}
}
Encoder is the same as in the basic concepts tutorial, essentially. However, since the simulation outputs a CSV file with the evolution of output variables over time we want the SimpleCSV decoder. The arguments to it should be self explanatory.
[8]:
encoder = uq.encoders.GenericEncoder(template_fname='sir.template', delimiter='$', target_filename='input.json')
decoder = uq.decoders.SimpleCSV(target_filename='output.csv', output_columns=['I'])
[9]:
campaign = uq.Campaign(name='sir', params=params, encoder=encoder, decoder=decoder)
We assume that the infection rate \(\beta\) is uniformly distributed between 0.15 and 0.25 and the recovery rate \(\gamma\) is normally distributed with mean 0.04 and small variance.
[10]:
vary = {
"beta": cp.Uniform(0.15, 0.25),
"gamma": cp.Normal(0.04, 0.01),
}
For this tutorial we will use Polynomial Chaos Expansion method. However, both SCSampler and QMCSampler would work as well and might be preferable depending on the case.
[11]:
campaign.set_sampler(uq.sampling.PCESampler(vary=vary, polynomial_order=5))
[12]:
execution = campaign.sample_and_apply(action=uq.actions.ExecuteLocalV2("sir input.json"), batch_size=8).start()
[17]:
execution.progress()
[17]:
{'ready': 0, 'active': 0, 'finished': 36, 'failed': 0}
[18]:
result = campaign.analyse(qoi_cols=['I'])
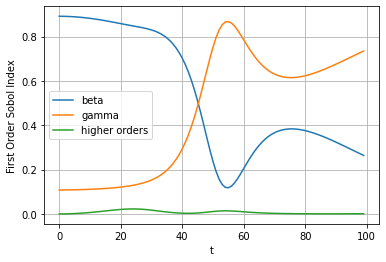
We can now see the results of the analysis. One thing to try would be to plot the first order sobol indices over time. This shows us how much influence the two parameters (beta and gamma) have over the number of people infected over time t. The higher orders line is meant to represent the influence of the interactions between the input variables. However it is negligible in this case.
[19]:
result.plot_sobols_first('I', xlabel='t')
[19]:
<AxesSubplot:xlabel='t', ylabel='First Order Sobol Index'>
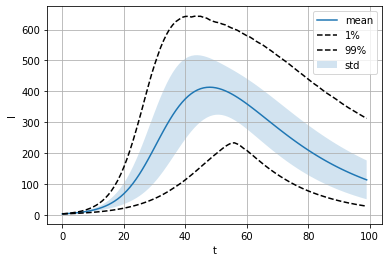
Finally we can try and visualize certain aspects of the distribution for our quantity of interest (number of infected people) over time. In this plot we will plot the mean value, standard deviation and 0.01 and 0.99 quantiles. This is with respect to the input variable distributions we have specified in the vary dictionary.
[20]:
result.plot_moments('I', xlabel='t')
[20]:
<AxesSubplot:xlabel='t', ylabel='I'>
If you want to access all of this data for processing you can use the following methods. Due to large output I have not evaluated these cells.
[ ]:
result.sobols_first('I')
[ ]:
result.describe('I', 'mean')
[ ]:
result.describe('I', 'std')
[ ]:
result.describe('I', '1%')
[ ]:
result.describe('I', '99%')
