Run the fusion EasyVVUQ campaign using PCE
Run an EasyVVUQ campaign to analyze the sensitivity of the temperature profile predicted by a simplified model of heat conduction in a tokamak plasma.
This is done with PCE.
[1]:
# import packages that we will use
%matplotlib inline
import os
import easyvvuq as uq
import chaospy as cp
import pickle
import time
import numpy as np
import pandas as pd
import matplotlib
if not os.getenv("DISPLAY"): matplotlib.use('Agg')
import matplotlib.pylab as plt
from IPython.display import display
%matplotlib inline
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/__init__.py:9: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
import pkg_resources
[2]:
# we need fipy -- install if not already available
try:
import fipy
except ModuleNotFoundError:
! pip install future
! pip install fipy
import fipy
[3]:
# routine to write out (if needed) the fusion .template file
def write_template(params):
str = ""
first = True
for k in params.keys():
if first:
str += '{"%s": "$%s"' % (k,k) ; first = False
else:
str += ', "%s": "$%s"' % (k,k)
str += '}'
print(str, file=open('fusion.template','w'))
[4]:
# define parameters of the fusion model
def define_params():
return {
"Qe_tot": {"type": "float", "min": 1.0e6, "max": 50.0e6, "default": 2e6},
"H0": {"type": "float", "min": 0.00, "max": 1.0, "default": 0},
"Hw": {"type": "float", "min": 0.01, "max": 100.0, "default": 0.1},
"Te_bc": {"type": "float", "min": 10.0, "max": 1000.0, "default": 100},
"chi": {"type": "float", "min": 0.01, "max": 100.0, "default": 1},
"a0": {"type": "float", "min": 0.2, "max": 10.0, "default": 1},
"R0": {"type": "float", "min": 0.5, "max": 20.0, "default": 3},
"E0": {"type": "float", "min": 1.0, "max": 10.0, "default": 1.5},
"b_pos": {"type": "float", "min": 0.95, "max": 0.99, "default": 0.98},
"b_height": {"type": "float", "min": 3e19, "max": 10e19, "default": 6e19},
"b_sol": {"type": "float", "min": 2e18, "max": 3e19, "default": 2e19},
"b_width": {"type": "float", "min": 0.005, "max": 0.025, "default": 0.01},
"b_slope": {"type": "float", "min": 0.0, "max": 0.05, "default": 0.01},
"nr": {"type": "integer", "min": 10, "max": 1000, "default": 100},
"dt": {"type": "float", "min": 1e-3, "max": 1e3, "default": 100},
"out_file": {"type": "string", "default": "output.csv"}
}
[5]:
# define varying quantities
def define_vary():
vary_all = {
"Qe_tot": cp.Uniform(1.8e6, 2.2e6),
"H0": cp.Uniform(0.0, 0.2),
"Hw": cp.Uniform(0.1, 0.5),
"chi": cp.Uniform(0.8, 1.2),
"Te_bc": cp.Uniform(80.0, 120.0),
"a0": cp.Uniform(0.9, 1.1),
"R0": cp.Uniform(2.7, 3.3),
"E0": cp.Uniform(1.4, 1.6),
"b_pos": cp.Uniform(0.95, 0.99),
"b_height": cp.Uniform(5e19, 7e19),
"b_sol": cp.Uniform(1e19, 3e19),
"b_width": cp.Uniform(0.015, 0.025),
"b_slope": cp.Uniform(0.005, 0.020)
}
vary_2 = {
"Qe_tot": cp.Uniform(1.8e6, 2.2e6),
"Te_bc": cp.Uniform(80.0, 120.0)
}
vary_5 = {
"Qe_tot": cp.Uniform(1.8e6, 2.2e6),
"H0": cp.Uniform(0.0, 0.2),
"Hw": cp.Uniform(0.1, 0.5),
"chi": cp.Uniform(0.8, 1.2),
"Te_bc": cp.Uniform(80.0, 120.0)
}
vary_10 = {
"Qe_tot": cp.Uniform(1.8e6, 2.2e6),
"H0": cp.Uniform(0.0, 0.2),
"Hw": cp.Uniform(0.1, 0.5),
"chi": cp.Uniform(0.8, 1.2),
"Te_bc": cp.Uniform(80.0, 120.0),
"b_pos": cp.Uniform(0.95, 0.99),
"b_height": cp.Uniform(5e19, 7e19),
"b_sol": cp.Uniform(1e19, 3e19),
"b_width": cp.Uniform(0.015, 0.025),
"b_slope": cp.Uniform(0.005, 0.020)
}
return vary_5
[6]:
# define a model to run the fusion code directly from python, expecting a dictionary and returning a dictionary
def run_fusion_model(input):
import json
import fusion
qois = ["te", "ne", "rho", "rho_norm"]
del input['out_file']
return {q: v for q,v in zip(qois, [t.tolist() for t in fusion.solve_Te(**input, plots=False, output=False)])}
[7]:
# routine to run a PCE campaign
def run_pce_case(pce_order=2, local=True, dask=True, batch_size=os.cpu_count(), use_files=True):
"""
Inputs:
pce_order: order of the PCE expansion
local: if using Dask, whether to use the local option (True)
dask: whether to use dask (True)
batch_size: for the non Dask option, number of cases to run in parallel (16)
Outputs:
results_df: Pandas dataFrame containing inputs to and output from the model
results: Results of the PCE analysis
times: Information about the elapsed time for the various phases of the calculation
pce_order: pce_order
count: number of PCE samples
"""
if dask:
if local:
print('Running locally')
import multiprocessing.popen_spawn_posix
from dask.distributed import Client, LocalCluster
cluster = LocalCluster(threads_per_worker=1)
client = Client(cluster) # processes=True, threads_per_worker=1)
else:
print('Running using SLURM')
from dask.distributed import Client
from dask_jobqueue import SLURMCluster
cluster = SLURMCluster(
job_extra=['--qos=p.tok.openmp.2h', '--mail-type=end', '--mail-user=dpc@rzg.mpg.de', '-t 2:00:00'],
queue='p.tok.openmp',
cores=8,
memory='8 GB',
processes=8)
cluster.scale(32)
print(cluster)
print(cluster.job_script())
client = Client(cluster)
print(client)
else:
import concurrent.futures
# client = concurrent.futures.ProcessPoolExecutor(max_workers=batch_size)
client = concurrent.futures.ThreadPoolExecutor(max_workers=batch_size)
# client = None
times = np.zeros(7)
time_start = time.time()
time_start_whole = time_start
# Set up a fresh campaign called "fusion_pce."
my_campaign = uq.Campaign(name='fusion_pce.')
# Define parameter space
params = define_params()
# Create an encoder and decoder for PCE test app
if use_files:
encoder = uq.encoders.GenericEncoder(template_fname='fusion.template',
delimiter='$',
target_filename='fusion_in.json')
decoder = uq.decoders.SimpleCSV(target_filename="output.csv",
output_columns=["te", "ne", "rho", "rho_norm"])
execute = uq.actions.ExecuteLocal('python3 %s/fusion_model.py fusion_in.json' % (os.getcwd()))
actions = uq.actions.Actions(uq.actions.CreateRunDirectory('/tmp'),
uq.actions.Encode(encoder), execute, uq.actions.Decode(decoder))
else:
actions = uq.actions.Actions(uq.actions.ExecutePython(run_fusion_model))
# Add the app (automatically set as current app)
my_campaign.add_app(name="fusion", params=params, actions=actions)
time_end = time.time()
times[1] = time_end-time_start
print('Time for phase 1 = %.3f' % (times[1]))
time_start = time.time()
# Associate a sampler with the campaign
my_campaign.set_sampler(uq.sampling.PCESampler(vary=define_vary(), polynomial_order=pce_order))
my_campaign.draw_samples()
print('Number of samples = %s' % my_campaign.get_active_sampler().count)
time_end = time.time()
times[2] = time_end-time_start
print('Time for phase 2 = %.3f' % (times[2]))
time_start = time.time()
# Perform the actions
my_campaign.execute(pool=client).collate(progress_bar=True)
if dask:
client.close()
client.shutdown()
time_end = time.time()
times[3] = time_end-time_start
print('Time for phase 3 = %.3f' % (times[3]))
time_start = time.time()
# Collate the results
results_df = my_campaign.get_collation_result()
time_end = time.time()
times[4] = time_end-time_start
print('Time for phase 4 = %.3f' % (times[4]))
time_start = time.time()
# Post-processing analysis
results = my_campaign.analyse(qoi_cols=["te", "ne", "rho", "rho_norm"])
time_end = time.time()
times[5] = time_end-time_start
print('Time for phase 5 = %.3f' % (times[5]))
time_start = time.time()
# Save the results
pickle.dump(results, open('fusion_results.pickle','bw'))
time_end = time.time()
times[6] = time_end-time_start
print('Time for phase 6 = %.3f' % (times[6]))
times[0] = time_end - time_start_whole
return results_df, results, times, pce_order, my_campaign.get_active_sampler().count
[8]:
# routines for plotting the results
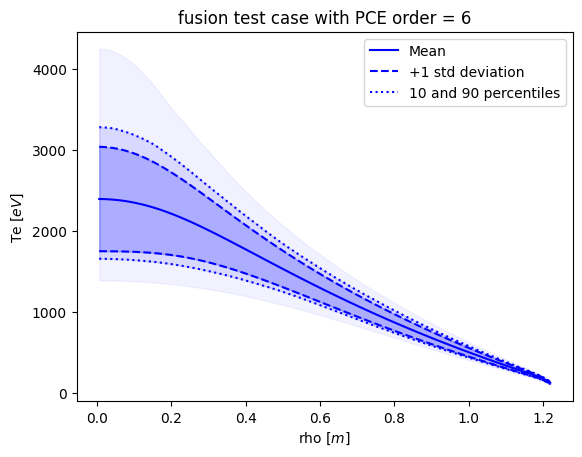
def plot_Te(results, title=None):
# plot the calculated Te: mean, with std deviation, 1, 10, 90 and 99%
plt.figure()
rho = results.describe('rho', 'mean')
plt.plot(rho, results.describe('te', 'mean'), 'b-', label='Mean')
plt.plot(rho, results.describe('te', 'mean')-results.describe('te', 'std'), 'b--', label='+1 std deviation')
plt.plot(rho, results.describe('te', 'mean')+results.describe('te', 'std'), 'b--')
plt.fill_between(rho, results.describe('te', 'mean')-results.describe('te', 'std'), results.describe('te', 'mean')+results.describe('te', 'std'), color='b', alpha=0.2)
plt.plot(rho, results.describe('te', '10%'), 'b:', label='10 and 90 percentiles')
plt.plot(rho, results.describe('te', '90%'), 'b:')
plt.fill_between(rho, results.describe('te', '10%'), results.describe('te', '90%'), color='b', alpha=0.1)
plt.fill_between(rho, results.describe('te', '1%'), results.describe('te', '99%'), color='b', alpha=0.05)
plt.legend(loc=0)
plt.xlabel('rho [$m$]')
plt.ylabel('Te [$eV$]')
if not title is None: plt.title(title)
plt.savefig('Te.png')
plt.savefig('Te.pdf')
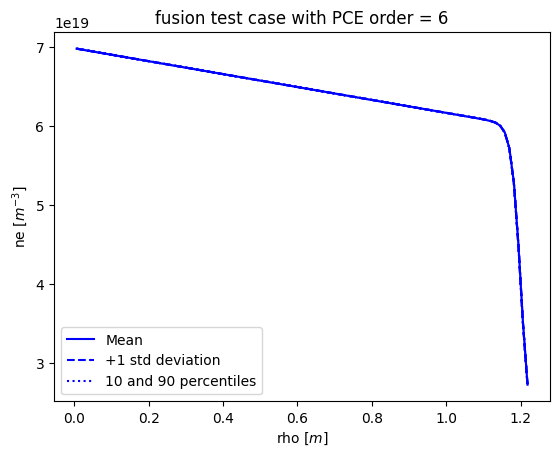
def plot_ne(results, title=None):
# plot the calculated ne: mean, with std deviation, 1, 10, 90 and 99%
plt.figure()
rho = results.describe('rho', 'mean')
plt.plot(rho, results.describe('ne', 'mean'), 'b-', label='Mean')
plt.plot(rho, results.describe('ne', 'mean')-results.describe('ne', 'std'), 'b--', label='+1 std deviation')
plt.plot(rho, results.describe('ne', 'mean')+results.describe('ne', 'std'), 'b--')
plt.fill_between(rho, results.describe('ne', 'mean')-results.describe('ne', 'std'), results.describe('ne', 'mean')+results.describe('ne', 'std'), color='b', alpha=0.2)
plt.plot(rho, results.describe('ne', '10%'), 'b:', label='10 and 90 percentiles')
plt.plot(rho, results.describe('ne', '90%'), 'b:')
plt.fill_between(rho, results.describe('ne', '10%'), results.describe('ne', '90%'), color='b', alpha=0.1)
plt.fill_between(rho, results.describe('ne', '1%'), results.describe('ne', '99%'), color='b', alpha=0.05)
plt.legend(loc=0)
plt.xlabel('rho [$m$]')
plt.ylabel('ne [$m^{-3}$]')
if not title is None: plt.title(title)
plt.savefig('ne.png')
plt.savefig('ne.pdf')
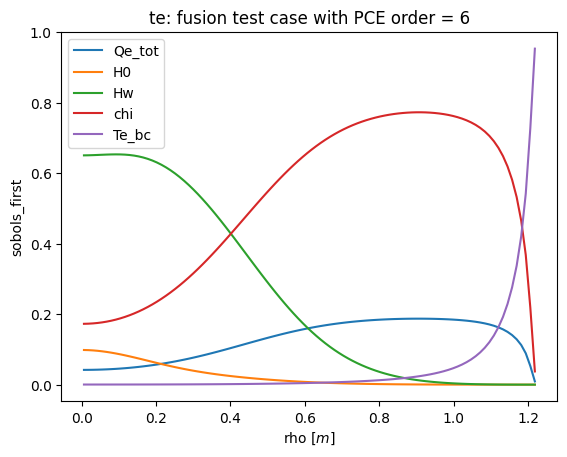
def plot_sobols_first(results, title=None, field='te'):
# plot the first Sobol results
plt.figure()
rho = results.describe('rho', 'mean')
for k in results.sobols_first()[field].keys(): plt.plot(rho, results.sobols_first()[field][k], label=k)
plt.legend(loc=0)
plt.xlabel('rho [$m$]')
plt.ylabel('sobols_first')
if not title is None: plt.title(field + ': ' + title)
plt.savefig('sobols_first_%s.png' % (field))
plt.savefig('sobols_first_%s.pdf' % (field))
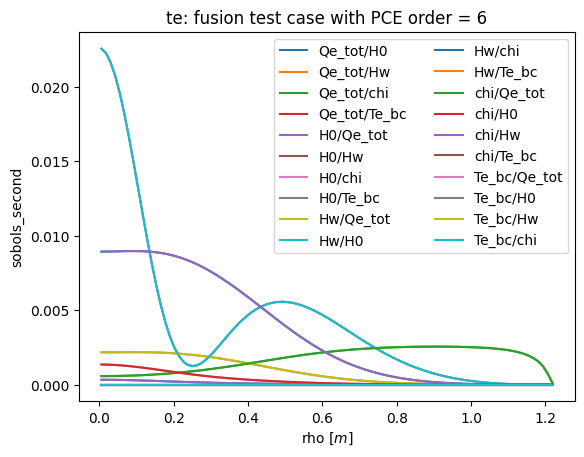
def plot_sobols_second(results, title=None, field='te'):
# plot the second Sobol results
plt.figure()
rho = results.describe('rho', 'mean')
for k1 in results.sobols_second()[field].keys():
for k2 in results.sobols_second()[field][k1].keys():
plt.plot(rho, results.sobols_second()[field][k1][k2], label=k1+'/'+k2)
plt.legend(loc=0, ncol=2)
plt.xlabel('rho [$m$]')
plt.ylabel('sobols_second')
if not title is None: plt.title(field + ': ' + title)
plt.savefig('sobols_second_%s.png' % (field))
plt.savefig('sobols_second_%s.pdf' % (field))
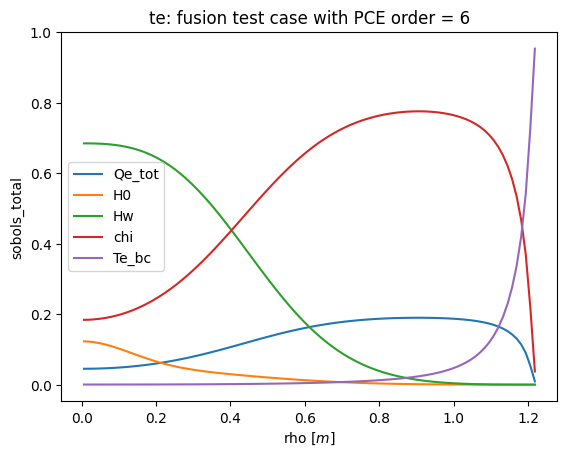
def plot_sobols_total(results, title=None, field='te'):
# plot the total Sobol results
plt.figure()
rho = results.describe('rho', 'mean')
for k in results.sobols_total()[field].keys(): plt.plot(rho, results.sobols_total()[field][k], label=k)
plt.legend(loc=0)
plt.xlabel('rho [$m$]')
plt.ylabel('sobols_total')
if not title is None: plt.title(field + ': ' + title)
plt.savefig('sobols_total_%s.png' % (field))
plt.savefig('sobols_total_%s.pdf' % (field))
def plot_distribution(results, results_df, title=None):
te_dist = results.raw_data['output_distributions']['te']
rho_norm = results.describe('rho_norm', 'mean')
plt.subplots(3,3,figsize=(12,12))
ip=0
for i in [np.maximum(0, int(i-1))
for i in np.linspace(0,1,9) * rho_norm.shape]:
ip += 1
plt.subplot(3,3,ip)
pdf_raw_samples = cp.GaussianKDE(results_df.te[i])
pdf_kde_samples = cp.GaussianKDE(te_dist.samples[i])
plt.hist(results_df.te[i], density=True, bins=50, label='histogram of raw samples', alpha=0.25)
if hasattr(te_dist, 'samples'):
plt.hist(te_dist.samples[i], density=True, bins=50, label='histogram of kde samples', alpha=0.25)
plt.plot(np.linspace(pdf_raw_samples.lower, pdf_raw_samples.upper), pdf_raw_samples.pdf(np.linspace(pdf_raw_samples.lower, pdf_raw_samples.upper)), label='PDF (raw samples)')
plt.plot(np.linspace(pdf_kde_samples.lower, pdf_kde_samples.upper), pdf_kde_samples.pdf(np.linspace(pdf_kde_samples.lower, pdf_kde_samples.upper)), label='PDF (kde samples)')
plt.legend(loc=0)
plt.xlabel('Te [$eV$]')
plt.title('Distributions for rho_norm = %0.4f' % (rho_norm[i]))
plt.subplots_adjust(left=0.05, right=0.95, bottom=0.05, top=0.925, wspace=0.4, hspace=0.3)
if not title is None: plt.suptitle(title)
plt.savefig('distribution_function.png')
plt.savefig('distribution_function.pdf')
[9]:
# Calculate the polynomial chaos expansion for a range of orders
if __name__ == '__main__':
local = False # if True, use local cores; if False, use SLURM
dask = False # if True, use DASK; if False, use a fall-back non-DASK option
R = {}
for pce_order in range(1, 7):
R[pce_order] = {}
(R[pce_order]['results_df'],
R[pce_order]['results'],
R[pce_order]['times'],
R[pce_order]['order'],
R[pce_order]['number_of_samples']) = run_pce_case(pce_order=pce_order,
local=local, dask=dask,
batch_size=7, use_files=False)
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/cerberus/validator.py:618: UserWarning: These types are defined both with a method and in the'types_mapping' property of this validator: {'integer'}
warn(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/cerberus/validator.py:618: UserWarning: These types are defined both with a method and in the'types_mapping' property of this validator: {'integer'}
warn(
Time for phase 1 = 0.018
Number of samples = 32
Time for phase 2 = 0.049
100%|███████████████████████████████████████████| 32/32 [00:00<00:00, 72.46it/s]
Time for phase 3 = 0.457
Time for phase 4 = 0.006
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: divide by zero encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: overflow encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: invalid value encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
Traceback (most recent call last):
File "/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/easyvvuq/analysis/pce_analysis.py", line 498, in analyse
dY_hat = build_surrogate_der(fit, verbose=False)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/easyvvuq/analysis/pce_analysis.py", line 338, in build_surrogate_der
assert(n1 == n2)
^^^^^^^^
AssertionError
Traceback (most recent call last):
File "/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/easyvvuq/analysis/pce_analysis.py", line 498, in analyse
dY_hat = build_surrogate_der(fit, verbose=False)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/easyvvuq/analysis/pce_analysis.py", line 338, in build_surrogate_der
assert(n1 == n2)
^^^^^^^^
AssertionError
Traceback (most recent call last):
File "/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/easyvvuq/analysis/pce_analysis.py", line 498, in analyse
dY_hat = build_surrogate_der(fit, verbose=False)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/easyvvuq/analysis/pce_analysis.py", line 338, in build_surrogate_der
assert(n1 == n2)
^^^^^^^^
AssertionError
Time for phase 5 = 0.726
Time for phase 6 = 0.014
Time for phase 1 = 0.005
Number of samples = 243
Time for phase 2 = 0.139
100%|█████████████████████████████████████████| 243/243 [00:03<00:00, 78.23it/s]
Time for phase 3 = 3.185
Time for phase 4 = 0.025
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: divide by zero encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: overflow encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: invalid value encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
Time for phase 5 = 3.443
Time for phase 6 = 0.016
Time for phase 1 = 0.005
Number of samples = 1024
Time for phase 2 = 0.515
100%|███████████████████████████████████████| 1024/1024 [00:14<00:00, 72.49it/s]
Time for phase 3 = 14.287
Time for phase 4 = 0.114
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: divide by zero encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: overflow encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: invalid value encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
Time for phase 5 = 13.609
Time for phase 6 = 0.019
Time for phase 1 = 0.009
Number of samples = 3125
Time for phase 2 = 1.334
100%|███████████████████████████████████████| 3125/3125 [00:43<00:00, 71.03it/s]
Time for phase 3 = 44.234
Time for phase 4 = 0.332
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: divide by zero encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: overflow encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: invalid value encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
Time for phase 5 = 60.253
Time for phase 6 = 0.026
Time for phase 1 = 0.014
Number of samples = 7776
Time for phase 2 = 2.977
100%|███████████████████████████████████████| 7776/7776 [01:43<00:00, 75.37it/s]
Time for phase 3 = 103.546
Time for phase 4 = 0.885
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: divide by zero encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: overflow encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: invalid value encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
Time for phase 5 = 255.867
Time for phase 6 = 0.033
Time for phase 1 = 0.010
Number of samples = 16807
Time for phase 2 = 6.281
100%|█████████████████████████████████████| 16807/16807 [03:40<00:00, 76.19it/s]
Time for phase 3 = 221.146
Time for phase 4 = 2.180
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: divide by zero encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: overflow encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/distributions/kernel/baseclass.py:84: RuntimeWarning: invalid value encountered in matmul
self._pcovariance = numpy.matmul(numpy.matmul(
/Volumes/UserData/dpc/GIT/EasyVVUQ/env/lib/python3.12/site-packages/chaospy/descriptives/correlation/pearson.py:45: RuntimeWarning: invalid value encountered in sqrt
vvar = numpy.sqrt(numpy.outer(var, var))
Time for phase 5 = 961.891
Time for phase 6 = 0.065
[10]:
# save the results
if __name__ == '__main__':
pickle.dump(R, open('collected_results.pickle','bw'))
[11]:
# produce a table of the time taken for various phases
# the phases are:
# 1: creation of campaign
# 2: creation of samples
# 3: running the cases
# 4: calculation of statistics including Sobols
# 5: returning of analysed results
# 6: saving campaign and pickled results
if __name__ == '__main__':
Timings = pd.DataFrame(np.array([R[r]['times'] for r in list(R.keys())]),
columns=['Total', 'Phase 1', 'Phase 2', 'Phase 3', 'Phase 4', 'Phase 5', 'Phase 6'],
index=[R[r]['order'] for r in list(R.keys())])
Timings.to_csv(open('Timings.csv', 'w'))
display(Timings)
| Total | Phase 1 | Phase 2 | Phase 3 | Phase 4 | Phase 5 | Phase 6 | |
|---|---|---|---|---|---|---|---|
| 1 | 1.270956 | 0.018249 | 0.049477 | 0.457251 | 0.006136 | 0.725576 | 0.014101 |
| 2 | 6.813447 | 0.004716 | 0.139352 | 3.184508 | 0.024941 | 3.443412 | 0.016367 |
| 3 | 28.555106 | 0.005205 | 0.515448 | 14.287420 | 0.113977 | 13.609176 | 0.019068 |
| 4 | 106.189113 | 0.009365 | 1.334293 | 44.234357 | 0.332101 | 60.252722 | 0.025862 |
| 5 | 363.321228 | 0.013717 | 2.976511 | 103.546055 | 0.884662 | 255.866825 | 0.032947 |
| 6 | 1191.574097 | 0.010267 | 6.280999 | 221.146430 | 2.179955 | 961.891130 | 0.064794 |
[12]:
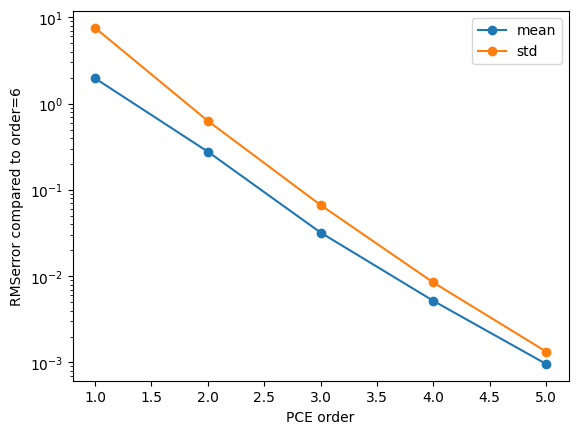
# plot the convergence of the mean and standard deviation to that of the highest order
if __name__ == '__main__':
last = -1
O = [R[r]['order'] for r in list(R.keys())]
if len(O[0:last]) > 0:
plt.figure()
plt.semilogy([o for o in O[0:last]],
[np.sqrt(np.mean((R[o]['results'].describe('te', 'mean') -
R[O[last]]['results'].describe('te', 'mean'))**2)) for o in O[0:last]],
'o-', label='mean')
plt.semilogy([o for o in O[0:last]],
[np.sqrt(np.mean((R[o]['results'].describe('te', 'std') -
R[O[last]]['results'].describe('te', 'std'))**2)) for o in O[0:last]],
'o-', label='std')
plt.xlabel('PCE order')
plt.ylabel('RMSerror compared to order=%s' % (O[last]))
plt.legend(loc=0)
plt.savefig('Convergence_mean_std.png')
plt.savefig('Convergence_mean_std.pdf')
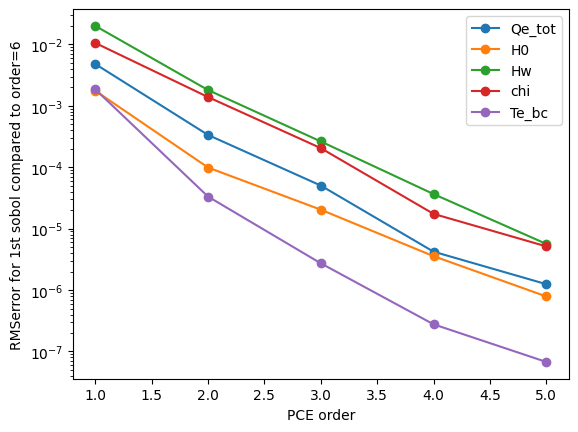
[13]:
# plot the convergence of the first sobol to that of the highest order
if __name__ == '__main__':
last = -1
O = [R[r]['order'] for r in list(R.keys())]
if len(O[0:last]) > 0:
plt.figure()
O = [R[r]['order'] for r in list(R.keys())]
for v in list(R[O[last]]['results'].sobols_first('te').keys()):
plt.semilogy([o for o in O[0:last]],
[np.sqrt(np.mean((R[o]['results'].sobols_first('te')[v] -
R[O[last]]['results'].sobols_first('te')[v])**2)) for o in O[0:last]],
'o-',
label=v)
plt.xlabel('PCE order')
plt.ylabel('RMSerror for 1st sobol compared to order=%s' % (O[last]))
plt.legend(loc=0)
plt.savefig('Convergence_sobol_first.png')
plt.savefig('Convergence_sobol_first.pdf')
[14]:
# plot a standard set of graphs for the highest order case
if __name__ == '__main__':
last = -1
title = 'fusion test case with PCE order = %i' % list(R.values())[last]['order']
plot_Te(list(R.values())[last]['results'], title=title,)
plot_ne(list(R.values())[last]['results'], title=title)
plot_sobols_first(list(R.values())[last]['results'], title=title)
plot_sobols_second(list(R.values())[last]['results'], title=title)
plot_sobols_total(list(R.values())[last]['results'], title=title)
plot_distribution(list(R.values())[last]['results'], list(R.values())[last]['results_df'], title=title)
plot_sobols_first(list(R.values())[last]['results'], title=title, field='ne')
plot_sobols_second(list(R.values())[last]['results'], title=title, field='ne')
plot_sobols_total(list(R.values())[last]['results'], title=title, field='ne')
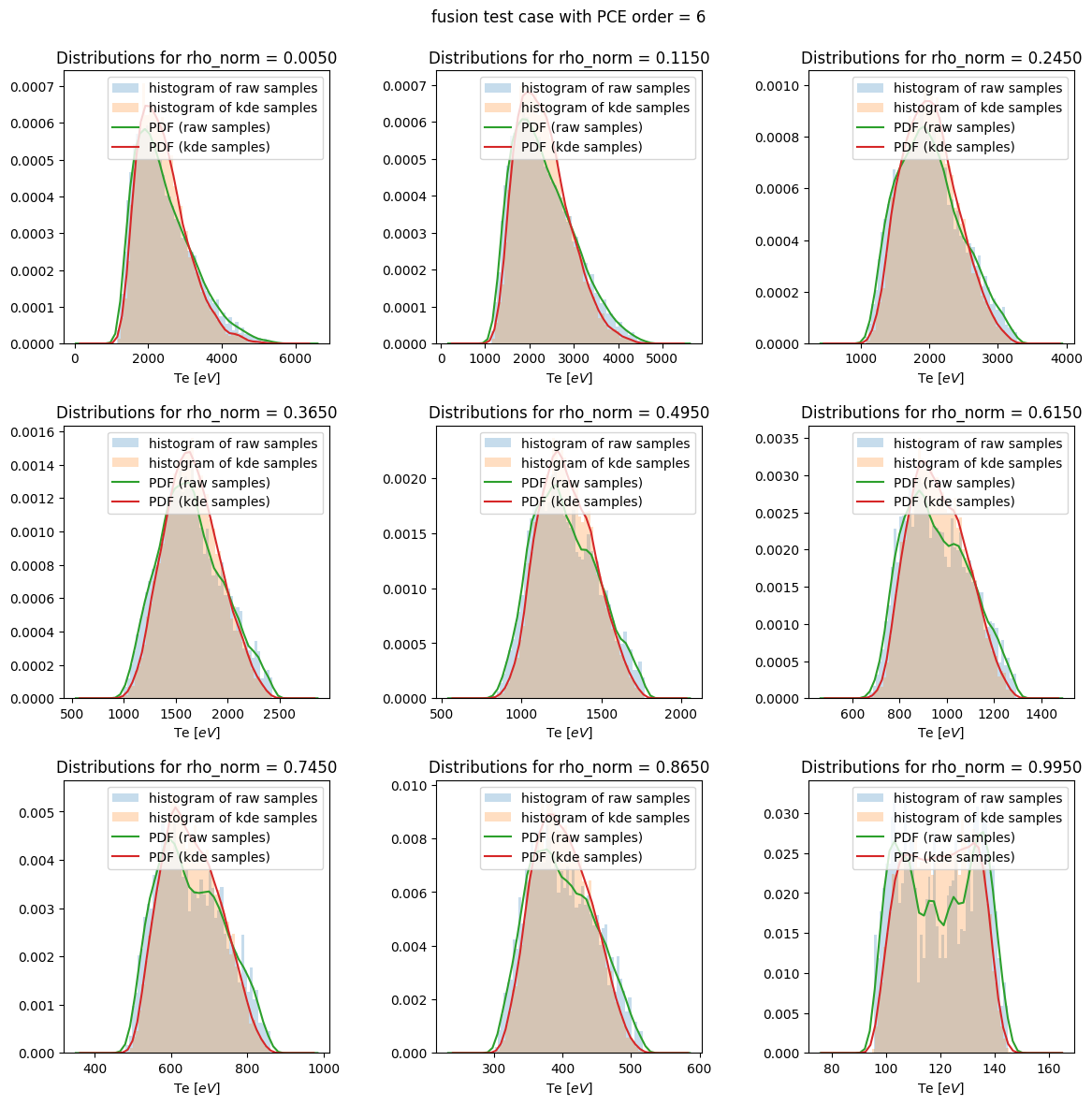
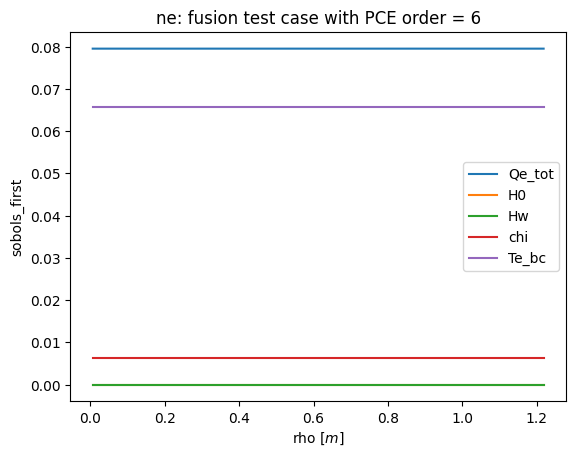
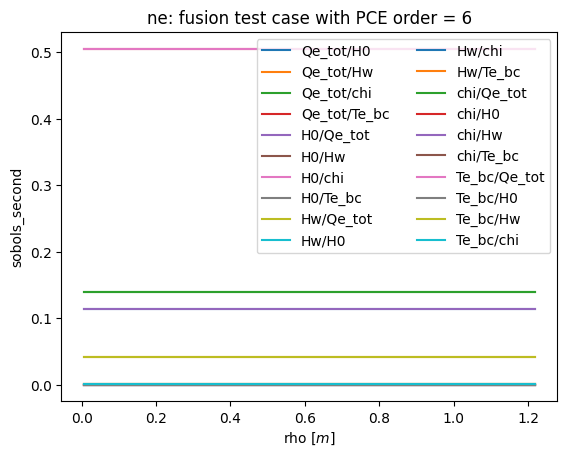
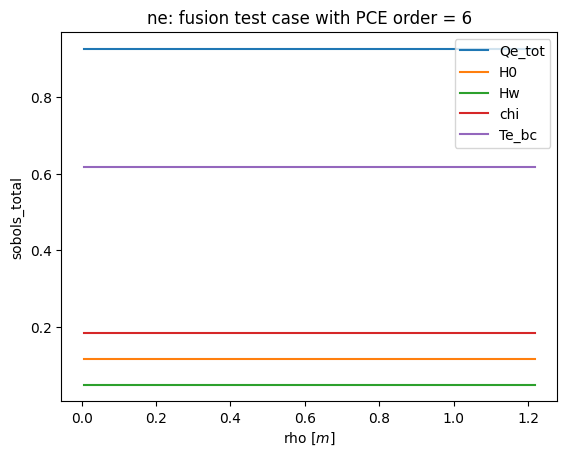
[15]:
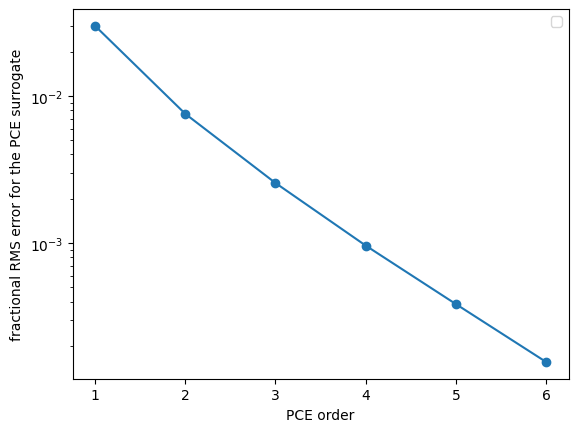
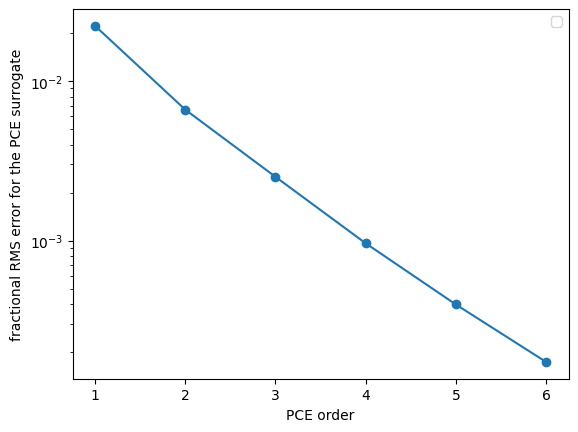
# plot the convergence of the surrogate based on the PCE points ()
if __name__ == '__main__':
_o = []
_RMS = []
for r in R.values():
results_df = r['results_df']
results = r['results']
te_surrogate = np.squeeze(np.array(results.surrogate()(results_df[results.inputs])['te']))
te_samples = np.array(results_df['te'])
_RMS.append((np.sqrt((((te_surrogate - te_samples) / te_samples)**2).mean())))
_o.append(r['order'])
plt.figure()
plt.semilogy(_o, _RMS, 'o-')
plt.xlabel('PCE order')
plt.ylabel('fractional RMS error for the PCE surrogate')
plt.legend(loc=0)
plt.savefig('Convergence_surrogate.png')
plt.savefig('Convergence_surrogate.pdf')
/var/folders/_0/dx4n8sh94h107t1d3g7wjwbm0000gn/T/ipykernel_2350/1999192989.py:17: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend(loc=0)
[16]:
# prepare the test data
if __name__ == '__main__':
test_campaign = uq.Campaign(name='fusion_pce.')
# Add the app (automatically set as current app)
test_campaign.add_app(name="fusion", params=define_params(),
actions=uq.actions.Actions(uq.actions.ExecutePython(run_fusion_model)))
# Associate a sampler with the campaign
test_campaign.set_sampler(uq.sampling.quasirandom.LHCSampler(vary=define_vary(), count=100))
# Perform the actions
test_campaign.execute(nsamples=1000).collate(progress_bar=True)
# Collate the results
test_df = test_campaign.get_collation_result()
100%|███████████████████████████████████████| 1000/1000 [00:13<00:00, 71.90it/s]
[17]:
# calculate the PCE surrogates
if __name__ == '__main__':
test_points = test_df[test_campaign.get_active_sampler().vary.get_keys()]
test_results = test_df['te'].values
test_predictions = {}
for i in list(R.keys()):
test_predictions[i] = np.squeeze(np.array(R[i]['results'].surrogate()(test_points)['te']))
[18]:
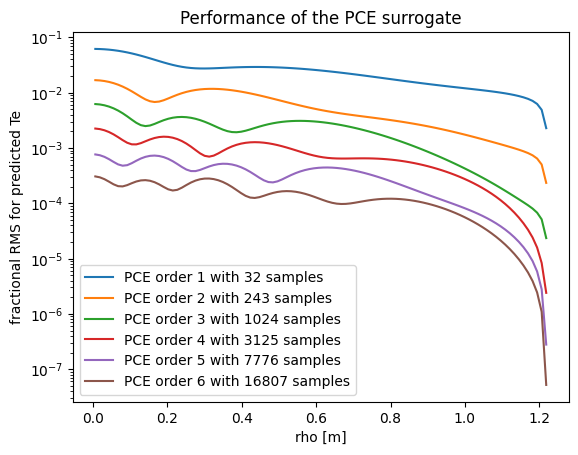
# plot the performance of the PCE surrogates
if __name__ == '__main__':
for i in list(R.keys()):
plt.semilogy(R[i]['results'].describe('rho', 'mean'),
np.sqrt(((test_predictions[i] - test_results)**2).mean(axis=0)) / test_results.mean(axis=0),
label='PCE order %s with %s samples' % (R[i]['order'], R[i]['number_of_samples']))
plt.xlabel('rho [m]') ; plt.ylabel('fractional RMS for predicted Te') ; plt.legend(loc=0)
plt.title('Performance of the PCE surrogate')
plt.savefig('PCE_surrogate.png')
plt.savefig('PCE_surrogate.pdf')
[19]:
# plot the convergence of the surrogate based on 1000 random points
if __name__ == '__main__':
_o = []
_RMS = []
for r in R.values():
_RMS.append((np.sqrt((((test_predictions[r['order']] - test_results) / test_results)**2).mean())))
_o.append(r['order'])
plt.figure()
plt.semilogy(_o, _RMS, 'o-')
plt.xlabel('PCE order')
plt.ylabel('fractional RMS error for the PCE surrogate')
plt.legend(loc=0)
plt.savefig('Convergence_PCE_surrogate.png')
plt.savefig('Convergence_PCE_surrogate.pdf')
/var/folders/_0/dx4n8sh94h107t1d3g7wjwbm0000gn/T/ipykernel_2350/2930361063.py:13: UserWarning: No artists with labels found to put in legend. Note that artists whose label start with an underscore are ignored when legend() is called with no argument.
plt.legend(loc=0)